
O desenvolvimento de sistemas de síntese de fala para várias línguas, nomeadamente os de síntese a partir de texto, tem vindo a contribuir poderosamente para aumentar a capacidade de comunicação de pessoas com deficiências de fala, com vantagens óbvias de um ponto de vista social sobre outros meios de apoio baseados na visualização de mensagens. Pelo menos idealmente, abre, de facto, o acesso à participação em várias situações de interacção verbal, permitindo lançar e intervir em conversas, de uma forma em tudo muito semelhante à que é utilizada pela generalidade dos membros da comunidade e beneficiando, tal como estes, do retorno imediato tanto do seu próprio discurso como das reacções que este provoca nos ouvintes. Faculta, ainda, o acesso a meios de comunicação, como o telefone por exemplo, sem que seja necessária a utilização de equipamento especial por parte dos interlocutores não deficientes. Na prática, porém, são ainda inúmeros os problemas que se levantam e impedem a sua utilização generalizada. Estes prendem-se, por um lado com dificuldades decorrentes da própria deficiência e, por outro, com a qualidade e naturalidade da fala sintética gerada pela maior parte dos sistemas existentes.
Um problema essencial é o da velocidade de geração das mensagens. Esta é sempre consideravelmente mais lenta do que nos falantes normais, mesmo quando não existe qualquer deficiência motora e podem ser executados movimentos finos e rápidos. Quando a deficiência de fala aparece associada a graves dificuldades de coordenação motora, escrever uma simples palavra exige normalmente um grande esforço físico e pode demorar vários minutos, suscitando por vezes reacções de impaciência por parte dos ouvintes e de ansiedade por parte dos utilizadores. Nos casos mais graves, nem sequer é possível a utilização directa do teclado, sendo necessário recorrer a outros dispositivos de apoio que permitam dactilografar mensagens ou seleccionar opções de comando utilizando os pés, a boca, a cabeça, etc.
Outro problema prende-se com o desempenho dos sintetizadores. De facto, contrariamente à ideia, durante algum tempo veiculada, de que a síntese de fala a partir de texto já não constituía um problema para ninguém, são ainda inúmeras as questões que se colocam tanto em termos gerais como do desenvolvimento de aplicações para fins específicos. A prová-lo está o relativo insucesso de muitos produtos desenvolvidos para outras línguas, pelo menos em parte, explicável pela falta de qualidade das vozes sintéticas produzidas. Estas estão ainda longe de poderem ser confundidas com vozes naturais, sendo necessário normalmente um período de adaptação às suas características para que se torne inteligível, sobretudo se a informação a fornecer for nova e inesperada. É necessário ainda, por conseguinte, um forte investimento a nível da investigação fundamental, tanto de um ponto de vista da linguística como da engenharia para preencher grande parte das lacunas existentes relativamente aos processos utilizados pelos falantes na produção de fala. Por outro lado, sendo os sistemas de síntese modelos de conversão de texto escrito em som, é necessário ter em consideração não só a especificidade dos inventários sonoros das línguas particulares e dos critérios subjacentes às suas ortografias, como as suas estruturas prosódicas e o modo como estas determinam os padrões rítmicos e melódicos e condicionam a forma como os segmentos são coarticulados quando concatenados em palavras ou em frases.
Como se chamou a atenção na proposta deste projecto, é necessário ter ainda em consideração o facto de a maior parte das aplicações desenvolvidas para apoio a pessoas com deficiência não utilizarem técnicas avançadas de síntese a partir de texto porque estas são ainda demasiado onerosas em memória ou em capacidade de cálculo e de difícil portabilidade. Embora os desenvolvimentos recentes na área da engenharia de computadores tenham permitido vir a alterar progressivamente esta situação, as técnicas mais avançadas implicam a utilização de recursos linguísticos básicos para as diferentes línguas particulares que, no caso da língua portuguesa são ainda insuficientes para assegurar um treino e teste adequados dos sistemas. O investimento que tem vindo a ser realizado a nível nacional tem ficado muito aquém do que tem tido lugar para a maioria das línguas da comunidade e o arranque da investigação básica na área da linguística computacional foi muito mais tardio. As equipas envolvidas são pequenas e os recursos linguísticos disponíveis são, por conseguinte, ainda escassos.
Apesar destas dificuldades, e dado que os sistemas de síntese podem também ser encarados como poderosos instrumentos de investigação tanto de um ponto de vista da linguística como da engenharia, foi desenvolvido de raiz um sistema de síntese para a língua portuguesa (DIXI). Desde a sua primeira versão (cf. Oliveira, Viana e Trancoso, 1991) que este sistema assegura todas as funções básicas necessárias para a conversão de texto para fala e tem sido preocupação constante das equipas envolvidas assegurar a participação em projectos que directa ou indirectamente pudessem contribuir para melhorar progressivamente o desempenho dos seus diferentes módulos. Apesar das suas limitações tanto em termos de inteligibilidade como de naturalidade, os técnicos que se ocupam de crianças com paralisia cerebral julgaram o seu desempenho francamente superior ao das adaptações feitas para o português de sistemas desenvolvidos para outras línguas e urgente a sua utilização como utensílio de apoio à aprendizagem da leitura e escrita e como meio de acesso à comunicação oral.
Foi essa a principal motivação para a proposta que esteve na origem do projecto "Sistema de Apoio Vocal para Pessoas com Deficiência Motora e de Fala" que, por uma questão de simplicidade passaremos a designar como EDIFALA, nome pelo qual é vulgarmente referido pelos membros das equipas envolvidas.
Este projecto serviu também de base à participação nos trabalhos do projecto europeu "Phrase Level Phonology", integrado no programa HCM (Human Capital Mobility), que se revestiu de grande interesse tanto de um ponto de vista da investigação fundamental sobre a língua portuguesa e sua comparação com outras analisadas no âmbito do projecto, como de um ponto de vista da sua modelização em computador. Como foi referido em relatórios anteriores, procurou-se, no entanto, seguir uma estratégia extremamente conservadora, utilizando sempre que possível os resultados obtidos para uma melhor modelização dos fenómenos mas evitando alterações drásticas a nível da sua estrutura geral que, pelo menos a curto prazo, poderiam redundar na perda da qualidade global do sistema como um todo. Os trabalhos realizados abrem, no entanto, perspectivas extremamente interessantes e motivadoras que pretendemos vir a explorar em futuros projectos de índole fundamental e aplicada na área da engenharia linguística, continuando a melhorar a qualidade da síntese do português europeu e desenvolvendo aplicações adequadas às necessidades de pessoas com outros tipos de deficiência, nomeadamente com deficiência visual.
Neste relatório, e tal como é expressamente solicitado pela JNICT, serão novamente enunciados os objectivos inicialmente propostos e referidas as principais alterações que tiveram lugar no que diz respeito ao faseamento das tarefas. Proceder-se-á, em seguida, à descrição do sistema de síntese DIXI, assim como dos trabalhos realizados para permitir uma melhoria da qualidade da voz sintética produzida. Segue-se uma descrição da interface com o utilizador (EDIXI), integralmente desenvolvida no decurso deste projecto e cujas especificações foram o resultado de um trabalho conjunto de engenheiros, linguistas e terapeutas trabalhando nesta área. Finalmente, serão referidos os resultados dos testes realizados junto dos seus utentes preferenciais e apresentadas as principais conclusões e perspectivas de trabalho futuro.
Voltar ao início do documentoO principal objectivo deste projecto foi o desenvolvimento de um protótipo de sistema de apoio vocal para pessoas com deficiência motora e de fala, baseado num editor de texto com saída vocal e capaz de fornecer uma voz artificial com qualidade suficiente para poder ser utilizada em diferentes situações de interacção verbal, tanto em casa como na escola ou no centro de reabilitação. Destinado prioritariamente a crianças e jovens com paralisia cerebral, pretendia-se construí-lo e aferí-lo com base nas suas necessidades, envolvendo-os como agentes activos de todo o processo.
Para a prossecução destes objectivos, as tarefas foram cuidadosamente faseadas e agrupadas em quatro grandes blocos com alguma sobreposição entre si:
1. Melhoria da qualidade do módulo de síntese de fala, nomeadamente através de um melhor controle da parametrização segmental e prosódica;
2. Desenvolvimento de um editor de texto adaptado a pessoas com deficiência motora e de fala, i.e., incluindo um conjunto de procedimentos destinados a reduzir os erros dactilografia e a acelerar a velocidade de geração das mensagens;
3. Integração do sistema de síntese no editor;
4. Teste das várias etapas de desenvolvimento do sistema, com objectivos pedagógicos, envolvendo a supervisão da reabilitação, e objectivos genéricos, relacionados com a melhoria da taxa de inteligibilidade do sintetizador e independentes da aplicação propriamente dita.
Voltar ao início do documento3. Alterações em relação ao plano inicial
Na sua generalidade, as tarefas inicialmente previstas foram levadas a bom termo, tendo sido possível atingir os objectivos propostos e, em alguns aspectos, até ultrapassá-los. Como é natural, no decurso do projecto foi necessário, contudo, proceder a alguns ajustamentos relativamente ao modo como estas tarefas foram faseadas. A maior parte das alterações foram motivadas pelos resultados dos trabalhos realizados e redundaram, de um modo geral, no alargamento dos tempos previstos para cada uma delas, permitindo o aprofundamento de questões que, de outra forma, não teriam sequer sido afloradas. Apenas num caso foi reduzido o tempo destinado a uma das tarefas: a que tinha por objectivo o teste do sistema por um conjunto de crianças do CPCCG. De facto, como adiante se descreverá com maior detalhe, foi completamente abandonada a ideia de desenvolver a aplicação com alguma limitações no que diz respeito à velocidade da síntese, irrelevantes dadas as limitações gerais de comunicação dos seus utentes preferenciais. A síntese em tempo real foi o objectivo prosseguido, tendo-se encarado a hipótese de funcionamento do sistema em tempo real em plataformas MS_DOS com uma placa dedicada, hipótese essa que foi também rapidamente abandonada, em favor de uma solução mais flexível e independente do hardware utilizado. A integração do editor e do sintetizador foi, assim, um processo mais lento do que previsto, não tendo sido julgado conveniente um investimento suplementar em versões intermédias com desempenhos que, à partida, se sabiam limitados e até desmotivadores. O teste do sistema decorreu, assim, apenas durante os últimos 9 meses, em vez dos dois anos inicialmente previstos, mas em condições muito mais favoráveis para um empenhamento real das crianças.
Não sendo necessário recorrer a hardware específico, o sistema torna-se facilmente recompilável podendo ser produzidas novas versões sempre que os progressos alcançados tanto a nível linguístico como de engenharia o justifiquem. Pôde encarar-se, por conseguinte, a hipótese de integrar um maior número de resultados do trabalho de investigação fundamental realizado no âmbito do projecto, razão pela qual foi decidido solicitar à JNICT autorização para um prolongamento de seis meses não envolvendo custos adicionais, autorização essa que foi concedida.
Voltar ao início do documento
O desenho e construção inicial do sistema DIXI foi determinado por um conjunto de objectivos considerados essenciais. Pretendia-se, fundamentalmente, construir um sistema de síntese, integralmente automático e com vocabulário ilimitado, correndo em tempo real em ambientes UNIX e MSDOS e estruturado de modo a poder vir a ser utilizado como ferramenta de investigação nas áreas da linguística e do processamento de sinal. O sistema deveria ainda ser suficientemente flexível e modular para poder ser facilmente integrado num vasto conjunto de aplicações e permitir uma incorporação fácil de outras variantes do Português.
Embora seja um facto bem conhecido que a síntese por concatenação permite obter melhores resultados em termos da inteligibilidade da fala sintética a mais curto prazo, a escolha recaíu num sistema de síntese por regra a partir de texto baseado no sintetizador de formantes de Klatt (1980). Trata-se de uma aposta a longo prazo, fundamentalmente ditada por duas razões: o interesse em desenvolver um modelo que permitisse integrar conhecimentos linguísticos e fonéticos desde o nível da representação fonológica abstracta até ao nível da geração de voz e a experiência prévia com a versão manual deste sintetizador, que mostrava ser possível dar conta da redução vocálica em Português Europeu (P.E.) de uma forma adequada (cf. Andrade, 1987).
O problema da redução vocálica também não é facilmente resolúvel, aliás, utilizando técnicas de síntese por concatenação, dado que exige a pré-gravação de um grande número de difones e sequências de duração variável ou, então, a sua extracção a partir de extensas bases de dados de fala etiquetadas e segmentadas. Uma vez que ainda era necessário recolhê-las e segmentá-las e que o processamento linguístico e a geração de contornos prosódicos é comum às duas técnicas de síntese, o fundamental era construir um sistema de síntese de formantes que permitisse o desenvolvimento e teste de modelos linguísticos adequados. Se o sistema fosse suficientemente modular, o seu bloco de geração de sinal poderia ser integralmente removido e substituído por outro, baseado em técnicas de concatenação, assim que os instrumentos necessários se encontrassem disponíveis.
A integração do sintetizador numa aplicação para pessoas com deficiência oro-motora implicava, no entanto, um maior investimento não só a nível dos módulos comuns aos diferentes tipos de técnicas mas também do módulo de geração dos parâmetros de controle do sintetizador de formantes, com o objectivo de aumentar a taxa de inteligibilidade da voz sintética produzida.
4.1. Estrutura geral e principais funções dos seus módulos
A organização geral do sistema, assim como os níveis de análise linguística e fonética assegurados, mantêm-se, na sua generalidade, idênticos desde a segunda versão (Oliveira, Viana e Trancoso, 1992) tendo sido feitas, contudo, algumas alterações na ordem de execução e na organização geral dos módulos, de modo a permitir uma mais fácil incorporação de novos conhecimentos aos diferentes níveis da estrutura e uma maior capacidade para servir de banco de ensaio de modelos linguísticos e de tratamento de sinal.
Figura 1 (retirada de Oliveira 1996)
Como se pode observar na figura 1, DIXI é actualmente constituído por seis módulos: normalização do texto escrito, conversão grafema-fone, análise prosódica, síntese da prosódia, transições subsegmentais e síntese propriamente dita, esta última assegurada por uma variante do sintetizador de formantes de Klatt (1980). Os quatro primeiros são comuns a qualquer tipo de sistema TTS; os dois últimos, específicos da classe de sistemas de síntese por regra de formantes.
Todo o código do sistema de síntese foi programado em linguagem C: directamente, no caso do primeiro e último módulos; com base no compilador de regras SCYLA ("Speech Compiler for Your LAnguage", desenvolvido pelo CSELT Itália; cf. Lazzareto e Nebia, 1987), no caso da maioria das funções dos módulos intermédios.
As principais razões para a escolha deste compilador prendem-se com o formato simples das regras e com o facto de este se basear em representações multilineares, gerando código C, que pode ser optimizado para o "hardware" onde vai funcionar e ligar-se a uma linguagem de procedimentos convencional para as operações mais facilmente codificáveis desta forma. Este compilador reúne, por conseguinte, os requisitos necessários para a utilização do sistema como instrumento de investigação em linguística e fonética, admitindo tanto modelos lineares como não lineares, eminentemente processuais ou declarativos (configuracionais), consoante as gramáticas que se pretenda testar.
O facto de todo o código estar escrito em C e de não necessitar de carregar ficheiros durante a execução aumenta a portabilidade do sistema. Tem ainda um debugger bastante poderoso, de grande utilidade para o desenvolvimento do sistema, que permite não só a visualização de cada uma das regras e dos seus resultados, dando conta da forma como a estrutura de dados vai sendo progressivamente preenchida, mas também a alteração manual desses resultados, para uma avaliação dos efeitos globais das alterações a introduzir. Quando utilizado em modo debugger, o sistema constrói ainda um ficheiro com a listagem das regras utilizadas, respeitando a ordem de execução das mesmas e permitindo, por conseguinte, uma análise detalhada dos efeitos de cada uma das acções desencadeadas.
O módulo de normalização (Carvalho, Geada e Lopes, 1992) como é habitual em sistemas similares, tem por função o pré-processamento do texto que é fornecido como entrada, transformando-o de modo a que possa ser processado pelo sistema. A ortografia da língua portuguesa utiliza caracteres complexos, contendo cedilhas e marcas de acento, normalmente representados em código ASCII estendido de 8 bits. Como se pretende que o sistema DIXI possa correr em várias plataformas e ser integrado em diferentes tipos de aplicações, e como nem todos os fabricantes de computadores e de programas respeitam as normas internacionalmente definidas para este conjunto alargado de caracteres, todos os caracteres de 8 bits são codificados com base em dois caracteres ASCII normais de 7 bits cada (ex: ç -> c,; à ->`a; á -> a´; ê -> e^; etc). Sendo a separação dos diacríticos uma forma habitual de representar caracteres complexos e não existindo uma norma que determine se estes devem preceder ou seguir os caracteres a que estão associados, este módulo também processa textos que já estejam codificados desta forma, considerando equivalentes todas as ordens possíveis e alterando as posições relativas de acordo com o seu formato interno (ex: {á, ´a, a´} -> a´).
Este módulo é ainda responsável pela detecção de abreviaturas comuns, de sequências de letras inadmissíveis em português ou de sequências com dígitos que têm de ser postas por extenso para poderem ser processadas. Qualquer sequência com dígitos que possa corresponder a uma data válida é convertida, como tal, em palavras, sendo todas as outras interpretadas como expressões numéricas ou sequências de números, de acordo com os caracteres gráficos utilizados como separadores. Alguns caracteres são traduzidos consoante o contexto em que se encontram inseridos.
A expansão de abreviaturas é feita com base num dicionário e num conjunto de regras que permitem decidir se as sequências de letras que não podem corresponder a palavras da língua portuguesa, devem ser lidas como tal ou simplesmente soletradas.
4.1.2 Processamento linguístico
No que diz respeito ao processamento linguístico propriamente dito, as soluções computacionais encontradas admitem estruturas de dados complexas e multidimensionais e a definição de tantos níveis de estrutura quantos os desejados. Todas as informações em cada nível (ou fiada) da representação multilinear são acessíveis a qualquer momento, podendo cada procedimento recorrer a informações representadas num só nível ou em vários níveis simultaneamente. Embora não seja a forma ideal de proceder, cada procedimento pode mesmo fazer apelo a informações que ainda não foram geradas pelo sistema, ficando suspensa a sua acção até que estas se encontrem disponíveis. Esta facilidade tem, evidentemente, implicações em termos de eficiência, sendo conveniente que todos os elementos necessários estejam disponíveis quando a acção que lhes faz apelo é desencadeada; mas foi, e continua a ser, extremamente útil para o desenvolvimento do sistema e para o teste de novas hipóteses.
Acesso ao léxico
O primeiro passo assegurado a nível de processamento linguístico é o acesso ao léxico, que consiste na associação de uma entrada do dicionário a cada palavra do enunciado aí encontrada. Desde a primeira versão que o dicionário apenas contém cerca de 800 entradas, com a seguinte estrutura: forma ortográfica normalizada, índice da posição do acento, transcrição fonética e indicações sobre a categoria e o possível comportamento gramatical:
ex: {"quatro", 2, "_k_w_a_t_r_u", _qnt, _foc}
Este dicionário, que pode ser aumentado ou substituído por outro de formato idêntico, contém fundamentalmente palavras gramaticais, advérbios e quantificadores, cuja informação é fundamental para o processamento sintáctico e prosódico. Algumas formas excepcionais em termos de pronúncia são também incluídas, sendo ainda contempladas, de entre as homógrafas heterofónicas, as mais frequentes.
Numa primeira etapa, já com base em SCYLA, é preenchida a primeira fiada (ou nível) da estrutura multi-linear com o texto normalizado, estando as marcas gráficas indicadoras da posição do acento associadas às vogais e ocupando com elas apenas uma posição. Dado que esta fiada é tomada como esqueleto da representação multilinear, sendo com ela que vão ser sincronizados todos os níveis da representação multidimensional, torna-se possível preencher outras fiadas com as informações extraídas do dicionário para cada palavra encontrada.
Processamento sintáctico
A partir destas informações, é efectuado o tratamento sintáctico que, à semelhança do que acontece com outros sistemas de síntese-por-regra a partir do texto, é extremamente elementar. A análise sintáctica é realizada tendo como base a identificação de marcas de pontuação e o conjunto de formas contidas no dicionário, cuja categoria é conhecida, sendo realizadas algumas operações que têm por objectivo identificar fronteiras de frase, determinar a modalidade destas e indicar a localização do verbo. Este conjunto de informações é essencial para o bom funcionamento dos submódulos que asseguram o processamento prosódico e a transcrição fonética.
Processamento morfológico
Dado que a ortografia do português pode ser considerada de base essencialmente fonológica e se pretende utilizar dicionários de pequena dimensão, a análise morfológica é também extremamente reduzida, limitando-se a fazer apelo a uma lista de radicais e afixos para identificar um conjunto de formas que necessitam de um tratamento especial de um ponto de vista da pronúncia: os compostos de radicais e as palavras derivadas por sufixação em -mente e Z-avaliativos. Trata-se de formas com dupla acentuação, cuja análise morfológica é imprescindível para uma correcta atribuição do acento secundário e, no caso dos compostos de radicais, também para evitar que a vogal de ligação seja processada como qualquer outra vogal átona no interior de uma palavra.
Transcrição fonética
Como a ortografia portuguesa é de base essencialmente fonológica, não são utilizados procedimentos intermédios de conversão grafema-fonema. Nos casos de e e o tónicos, em que a uma representação ortográfica podem corresponder duas representações fonológicas diferentes, é a vogal aberta que é considerada. Na ausência de um dicionário exaustivo, parece ser esta a opção que permite uma maior simplicidade de regras e um menor número de excepções.
As palavras sem marcas gráficas de acento ou que não se encontrem no dicionário são acentuadas pelo sistema, com base num conjunto de 18 regras escritas em C, mais eficientes mas basicamente semelhantes na sua concepção às utilizadas no conversor descrito em Andrade e Viana (1985). Tendo também como base esse mesmo trabalho e o efectuado posteriormente para melhorar o desempenho das regras aí propostas, o sub-módulo de transcrição fonética assegura a conversão directa de grafemas em fones com base num conjunto de cerca de 200 regras de reescrita. Apresenta, no entanto, consideráveis melhorias, em relação às versões anteriores, permitindo descrever um maior número de fenómenos, como os ditos de elisão e coalescência, tanto a nível da palavra como da frase e assegurando um desempenho global igual ou superior ao observado nas anteriores versões apenas para formas de citação. Para esse efeito e também para tornar o teste do modelo prosódico global mais fácil e produtivo, as regras que desencadeiam as diferentes operações estão organizadas em três conjuntos de procedimentos relativamente independentes mas que operam sobre os mesmos níveis de estruturas de dados. O primeiro efectua uma transcrição fonética larga ao nível da palavra, em que são preservadas todas as vogais átonas; o segundo actua sobre esta transcrição para dar conta de um conjunto de fenómenos sensíveis à estrutura prosódica a nível da palavra e da frase; e o terceiro assegura a partição dos segmentos da transcrição fonética larga em vários subsegmentos, o que permite a associação de algumas das posições da fiada segmental a mais do que uma posição na fiada temporal, assim como um mais fácil controle das associações tonais, em fronteira de constituinte entonacional.
Análise prosódica
O módulo de análise prosódica, embora utilizando o mesmo formato de regras de reescrita, não efectua quaisquer transformações, sendo irrelevante a ordem pela qual as regras são aplicadas. Limita-se, com efeito, a construir uma representação fonológica fortemente hierarquizada, com base em agrupamentos sucessivos desde o nível segmental ao nível do enunciado e utilizando, depois, um conjunto de estratégias para predizer o modo como este pode ser fraseado. A cada nível da estrutura são marcados os elementos proeminentes de cada constituinte, sendo possível distinguir globalmente 6 graus de acento que são representados numa fiada independente. Três dos acentos dão conta das relações de proeminência relativa ao nível da palavra, reflectindo os outros três o modo como estas se encontram agrupadas e sendo atribuídos, por conseguinte, depois de realizado o fraseamento predito pelas estratégias de partição. Trata-se, de um ponto de vista geral, de modelizar de um modo integrado os resultados dos trabalhos anteriores descritos em Viana (1987) e Andrade e Viana (1988, 1889), mas em pormenor contém algumas diferenças significativas em relação a estes trabalhos, integrando outros níveis da estrutura e estabelecendo diferentes relações de proeminência.
O preenchimento da fiada tonal da representação multilinear depende também do fraseamento efectuado: as melodias básicas são seleccionadas a partir de informações relativas à modalidade da frase e atribuídas ao nível da partição predita pelo sistema, sendo a sincronização dos tons com a fiada de posições métricas do esqueleto assegurada por um conjunto de regras também muito semelhantes às propostas em Viana (1987).
O módulo prosódico permite gerar, por conseguinte, uma representação abstracta a partir da qual vai ser possível predizer directamente a evolução temporal dos parâmetros prosódicos de duração, energia e frequência fundamental.
Síntese da prosódia
O desenho dos contornos prosódicos é a última etapa que se pode considerar comum aos sistemas de síntese por regra e aos que utilizam métodos de concatenação, gerando os contornos rítmicos e entonacionais.
De acordo com o valor do débito seleccionado pelo utilizador e recorrendo a tabelas com os valores médios utilizados pelo informante modelo, são estimados, em primeiro lugar, valores de duração silábica. A partir destes valores e tendo em consideração a estrutura interna da sílaba e os graus de proeminência relativa atribuídos pela análise prosódica, são calculados os valores de duração associados a cada posição da fiada temporal, com base num modelo multiplicativo que associa a cada um dos 6 acentos diferentes graus de compressão ou expansão intra e inter-silábica.
Este tratamento corresponde à extensão de estudos anteriores sobre o ritmo e o acento que permitiram mostrar que os graus de acento se manifestam foneticamente em termos das durações relativas tanto das sílabas como um todo como dos diferentes segmentos que as constituem: as sílabas sobre as quais recai o acento de palavra (tónicas) são consideravelmente mais longas do que as átonas e quanto maior é o grau de atonicidade de uma sílaba, mais pequena é a duração do seu núcleo relativamente ao seu ataque.
Para desenhar os contornos de F0 e de energia, o sistema utiliza linhas de referência, cujo comprimento e declive depende da organização temporal do enunciado.
Baseando-se no tratamento proposto em Viana (1987) mas, sobretudo em estudos posteriores que ainda não houve ocasião de publicar, são desenhadas pelo sistema linhas de referência para o escalonamento dos valores de F0 atribuídos aos segmentos da fiada tonal. A determinação dos pontos de ancoragem dos tons, isto é, do modo como se encontram associados à cadeia subsegmental, é feita por um conjunto de procedimentos que têm em consideração não só os acentos mas também o modo de vozeamento das consoantes adjacentes, predizendo diferentes tipos de associação e de evolução dos contornos de F0 em função de três grandes classes: sonantes, vozeadas e não vozeadas.
Transições sub-segmentais
O módulo de geração de transições subsegmentais traça as trajectórias dos vários parâmetros de controle do sintetizador de formantes, baseando-se no modelo de alvos e transições em Allen et al. (1987), em que as variáveis de transição definem o tipo de transição, as constantes de tempo de alisamento e as descontinuidades, como a figura 2 mostra.
A primeira etapa consiste numa busca de tabelas com valores de defeito de duração da transição e de valores alvo para os segmentos. Os valores alvo dos parâmetros são atribuídos de modo diferente do que é proposto pelos autores acima referidos, aos elementos da fiada subsegmental, sendo os pontos de ancoragem para a geração de transições sucessivamente localizados nas fronteiras de subsegmentos consecutivos. Trata-se de uma solução provisória que, não só evita o tratamento especial de certas classes de sons como as vibrantes, as oclusivas e as vogais nasais, como permite descrever com maior detalhe e com um menor número de regras alguns efeitos de coarticulação, sendo particularmente útil para um controle mais fino da distância entre o pólo e zero nasais e da quantidade de murmúrio nasal na transição entre vogais nasais e obstruintes.
|
|
|
Figura 2 (retirada de Oliveira, 1996) |
Repare-se, ainda, que há diferenças, também, no modo como são tratados os ditongos. Os elementos que os constituem são encarados como ocupando posições independentes na fiada segmental, sendo a temporização relativa das trajectórias de formantes dependentes não só da posição que ocupam na sílaba como do grau de proeminência desta.
Uma vez efectuadas estas operações, os parâmetros de controle do sintetizador são calculados em intervalos de 5 ms, usando interpolação linear.
Dado que o modelo prosódico atribui valores de compressão diferentes às vogais átonas estas podem desaparecer completamente ou serem de tal modo curtas que os valores das transições de e para os segmentos (ou subsegmentos) adjacentes se sobrepõem em certos contextos. Para evitar os efeitos perceptivos verdadeiramente indesejáveis que, então ocorrem, o sistema assegura o alisamento das transições, de acordo com uma sugestão em Holmes (1988) e tal como a figura 3, ilustra.
|
|
|
Figura 3 (retirada de Oliveira, 1996) |
O módulo final do sistema, o sintetizador propriamente dito, é uma variante do modelo proposto por Klatt (1980).
|
|
|
Figura 4 (retirada de Oliveira, 1996) |
A figura 4 mostra em detalhe este sintetizador, indicando a totalidade de parâmetros de controle disponíveis e marcando a negro os 18 que são, de momento, controlados dinamicamente pelo sistema: a frequência fundamental, a amplitude da excitação vozeada, as amplitudes das excitações não vozeadas dos modelos cascata e paralelo, 4 frequências de formantes, 3 larguras de banda de formantes, as frequências do pólo e zero nasais, 5 amplitudes de formantes para o modelo paralelo e uma amplitude de ruído de bypass directo.
4.2. Melhoria da qualidade da síntese do P.E.
A extrema modularidade e flexibilidade do sistema tornam-no num instrumento de investigação fundamental que permite o ensaio de modelos linguísticos e de produção de fala e uma avaliação qualitativa e quantitativa dos mesmos. Se é um facto inquestionável que são inúmeras as suas potencialidades, também é verdade que uma simulação adequada do comportamento dos falantes do Português Europeu não é uma tarefa simples que se possa assegurar a curto prazo, uma vez que exige um forte investimento em trabalhos de índole fundamental sobre as características desta língua que seria impossível realizar no quadro deste projecto. Repare-se, no entanto, que um sistema de síntese deste tipo pode, efectivamente, ser encarado como uma base de conhecimentos sobre as características e modo de funcionamento da língua para que é desenvolvido, assumindo-se geralmente que a qualidade da fala sintética produzida é um reflexo directo da adequação dos conhecimentos introduzidos. Embora esta questão não seja tão pacífica quanto pode parecer, na medida em que as diferentes componentes de um modelo não são totalmente independentes entre si, esses conhecimentos podem ser progressivamente introduzidos e testados, ainda que de modo parcelar, à medida que os resultados dos trabalhos de investigação fundamental forem estando disponíveis.
O facto de este sintetizador, mesmo na sua versão anterior a este projecto, ter sido julgado já de grande utilidade como instrumento de apoio a pessoas com deficiência, levou-nos a procurar colmatar algumas das suas principais lacunas e a melhorar, tanto quanto possível, o seu desempenho, mesmo que para tal fosse necessário recorrer a soluções de compromisso de carácter provisório. Na actual versão do sistema, por exemplo, as durações dos segmentos são exageradas, de modo a garantir uma maior inteligibilidade da fala sintética produzida, enquanto ainda se não conhece quais os ajustes que é necessário realizar para garantir que os segmentos continuem a ser facilmente identificados, mesmo quando a sua duração é drasticamente reduzida. Este facto não impediu, no entanto, que a partir de trabalhos de investigação fundamental tivessem sido introduzidos conhecimentos que permitem uma predição mais adequada das condições em que essa redução ocorre. O sistema é suficientemente flexível para permitir o teste parcial dessas condições, inibindo provisoriamente o processamento sobre resultados das acções desencadeadas até que se saiba quantificar os ajustes necessários e se possa assegurar uma melhor manipulação dos parâmetros de controle do sintetizador.
Nos trabalhos realizados para uma melhoria da parametrização segmental e prosódica foram utilizados diferentes corpora de controle, quer recolhidos no âmbito deste projecto especialmente para esse efeito quer de outros projectos anteriores já concluídos ou em curso, nomeadamente no âmbito dos projectos ESPRIT III 6819 SAM_A "Multi-Lingual Speech Input / Output, Methodology and Standardization" e JNICT - PLUS/C/LIN/801/93 "BDFALA: Base de Dados de Fala para o Português Europeu". Não se tratou, como já foi referido anteriormente (cf. Relatório de Execução Material correspondente ao 2º ano do projecto) de proceder a uma análise aprofundada desses corpora mas de seleccionar exemplos relevantes, sobretudo correspondentes às produções do locutor utilizado como modelo para a síntese, comparando-os com as formas correspondentes produzidas por DIXI e procurando aproximar as segundas das primeiras por tentativa e erro, procedimento que é habitual no desenvolvimento de sistemas deste tipo.
Para a prossecução destes objectivos foi fundamental poder dispor de uma versão manual do sintetizador de Klatt (1980), em que o sistema DIXI se baseia, e, já no decurso do último ano do projecto, de uma versão deste sintetizador contendo uma interface gráfica com o utilizador, de grande utilidade e eficiência. Esta interface, da autoria de A. Simpson, é ilustrada na figura 5, onde se apresentam as predições da actual versão do sistema no que diz respeito à evolução temporal dos quatro primeiros formantes para a palavra "velho".

Figura 5 - Interface gráfica do sintetizador manual de Klatt, da autoria de A. Simpson, em que é representada graficamente a evolução dos 4 primeiros formantes para a palavra "velho" tal como esta é predita pela actual versão do sistema DIXI.
Todos os parâmetros de controle do sintetizador indicados à esquerda do gráfico podem ser igualmente visualizados e manipulados, bastando para tal tornar activo o parâmetro que se pretende modificar (representado a cheio) e redesenhar com o rato a linha correspondente do ecrã.
Para utilizar as facilidades de manipulação destes programas e evitar a necessidade de recompilar constantemente todo o sistema de cada vez que é feito um novo ensaio, as saídas intermédias (opcionais) do sistema DIXI foram compatibilizadas com as entradas do sintetizador manual (programa de conversão automática), permitindo gerar automaticamente formas que se sabem inadequadas, recuperá-las com o sintetizador manual e modificá-las de modo a garantir uma maior aproximação às produções naturais do locutor de referência e resultados auditivamente mais satisfatórios. Uma vez encontrados valores alvo adequados e conhecidas as modificações que é necessário assegurar para dar conta da variação contextual, são estimadas as alterações a introduzir no sistema DIXI e novamente comparadas as suas produções com as naturais e com as sintéticas manuais consideradas satisfatórias, repetindo-se todo o processo, se necessário.
Outro procedimento utilizado no âmbito do projecto, sobretudo para o ajuste da parametrização prosódica, foi a sobreposição de elementos da fala sintética com elementos da fala natural. É difícil, com efeito, fazer uma ideia clara da aceitabilidade dos contornos prosódicos gerados pelo sistema porque os julgamentos dos ouvintes sobre a naturalidade destes são afectados por outros factores, tanto de ordem prosódica como segmental. Repare-se, por exemplo, que se as durações segmentais são propositadamente exageradas para preservar uma maior inteligibilidade segmental, o ritmo da frase é necessariamente alterado e o teste da adequação tanto dos contornos rítmicos como entonacionais comprometido.
No âmbito do projecto, foram assim utilizados dois procedimentos independentes mas complementares para testar e ajustar os diferentes tipos de parametrização:
- substituição manual dos valores de frequência fundamental, duração e energia dos segmentos na estrutura de dados de DIXI (compilado em modo ´debug´) por valores observados na fala natural para frases idênticas;
- modificação manual dos contornos rítmicos e entonacionais de frases naturais por contornos sintéticos preditos pelo sistema de síntese para as mesmas frases.
Estes meios adicionais são fundamentais para facilitar o teste de hipóteses e seleccionar a que permite uma maior adequação aos dados observados na fala natural, procurando-se, então, introduzi-la no sistema procedendo aos ajustes necessários também por tentativa e erro.
4.2.2.Controle da parametrização segmental
Algumas das lacunas mais graves, tal como mencionado desde a proposta do projecto, diziam respeito à geração das consoantes [´ ], [ø ] e [R ], cujas realizações em certos contextos eram francamente insatisfatórias ou mesmo ininteligíveis. Foi sobre estas, sobretudo, que incidiu o trabalho de adaptação e ajuste de parâmetros.
O ajuste temporal dos parâmetros por tentativa e erro é, reconhecidamente, um trabalho de grande morosidade. O tempo inicialmente calculado para a realização desta tarefa excedeu, no entanto, largamente o inicialmente previsto, calculado com alguma margem de segurança com base no tempo dispendido em projectos anteriores no ajuste dos parâmetros para outras classes de consoantes. Uma simulação mais adequada de [´ ] e [R ], ocupou cerca de 4 meses a tempo integral, tendo sido necessário dilatar o período previsto para a execução desta tarefa, de modo a poder realizar um investimento idêntico no ajuste dos valores alvo e no controle temporal dos diferentes parâmetros do sintetizador para a nasal [ø ] e a vibrante [{ ]. A geração de um [ø ] inteligível em diferentes contextos foi particularmente difícil, tendo apenas sido possível conseguir aproximações aceitáveis em diferentes contextos quase no fim do projecto. A morosidade deste trabalho explica-se, pelo menos em grande parte, pela inexistência de estudos prévios sobre as características acústicas destas consoantes, assim como de um corpus contemplando as suas realizações num número suficiente e controlável de contextos, tendo sido necessário recolhê-lo e analisá-lo com alguma sistematicidade.
O ajuste da parametrização segmental não se limitou, no entanto, apenas a uma melhor modelização destas consoantes, tendo sido introduzidas numerosas pequenas alterações em parâmetros associados a outras classes de sons, de modo a gerar sequências mais condizentes com as observadas na fala natural. Apenas a título de exemplo, refiram-se as alterações nos valores alvo de energia global e de amplitude dos formantes de algumas fricativas e as que asseguram um melhor controle da evolução temporal do pólo e zero nasais em diferentes contextos, nomeadamente com o objectivo de reduzir a quantidade de nasalidade atribuída às vogais orais imediatamente adjacentes a consoantes nasais em posição de ataque silábico e que era responsável por uma qualidade por vezes excessivamente nasalada da voz sintética.
Embora tal não tivesse sido previsto inicialmente, foram também realizadas algumas experiências de alteração das larguras de banda dos formantes e dos tempos de abertura e fechamento glotal, numa tentativa de diminuir o carácter excessivamente ´tenso´ da voz sintética produzida. Alguns pequenos testes informais comparando estímulos gerados com e sem alteração destes últimos parâmetros indicam, no entanto que estas não conduzem a mudanças significativas na qualidade da voz, pelo menos enquanto os segmentos forem sobrearticulados para preservar a inteligibilidade.
4.2.3 Controle da parametrização prosódica
No que diz respeito à prosódia, procurou-se continuar a fundamentar e a desenvolver um modelo em que são os agrupamentos e as relações de proeminência dos objectos fonológicos que controlam tanto a ocorrência de padrões rítmicos e entonacionais, como a variação na distribuição alofónica.
Os estudos conducentes a uma melhor compreensão das relações entre a estrutura prsódica e as propriedades físicas dos sons e as diferentes tentativas de simulação dos factos observados na fala natural, conduziram à revisão de alguns dos critérios adoptados na versão anterior do sistema, no que diz respeito aos agrupamento em sílabas e em pés. Os fenómenos fonéticos em fronteira de palavra, nomeadamente o modo como são resolvidos os encontros vocálicos, foram objecto de particular atenção, uma vez que, em conjunto com aspectos do ritmo e entoação, constituem importantes indícios dos constituintes prosódicos relevantes a nível da frase.
O alinhamento temporal dos elementos da fiada tonal, foi outra questão considerada com bastante detalhe, tendo sido realizados alguns testes informais com sobreposição de fala sintética e fala natural para avaliar da sua robustez de um ponto de vista perceptivo.
Nem todos os resultados destes trabalhos puderam, no entanto, ser incluídos no sistema, uma vez que este ainda não dispõe das informações necessárias a nível sintáctico e semântico.
4.3. Melhoria a nível da implementação do sistema
A integração do editor com o sintetizador era objecto da tarefa III, antecipada em relação aos prazos previstos e concluída com sucesso, ainda no decorrer do segundo ano do projecto. Este processo foi bastante mais longo e complexo do que inicialmente se tinha previsto, uma vez que, perante os desenvolvimentos recentes a nível das capacidades de memória e de cálculo dos computadores pessoais, não se justificava manter as propostas iniciais mas antes acompanhar essa evolução, tirando dela o melhor partido possível. Assim, e embora tivesse sido expressamente salientado na proposta inicial que o sintetizador não seria implementado num processador de sinal e que, por conseguinte, o protótipo apresentaria algumas limitações no que diz respeito à valocidade da síntese, a síntese em tempo real foi, de facto, um dos principais objectivos desta tarefa. Os trabalhos realizados para a prossecução deste objectivo foram os descritos no último relatório e a seguir reproduzidos.
Para assegurar a síntese em tempo real em ambiente MSDOS, o sintetizador de formantes foi inicialmente desenhado para correr numa placa dedicada mas os desenvolvimentos a nível do CPU e da memória tornaram possível uma implementação completa a correr em tempo real em MSDOS, mas como um processo único e requerendo a utilização de uma placa audio específica (a Sound Blaster 16). Com a generalização das capacidades multimédia, tornou-se praticamente obsoleto manter esta aplicação dependente de uma placa-audio específica. O progresso dos trabalhos foi, por conseguinte, o que passamos a descrever.
Em primeiro lugar, o DIXI foi dividido em dois grandes módulos: drawpar e parwave. O primeiro é responsável pelas funções de pré-processamento e pela geração de parâmetros de síntese e o segundo utiliza estes parâmetros para controlar um sintetizador Klatt produzindo o sinal de fala.
Em arquitecturas UNIX é possível correr o DIXI simplesmente passando a saída (output) de drawpar para parwave utilizando pipes (drawpar ¦ parwave). O objectivo foi o de separar o mais possível os módulos constituintes do sistema, permitindo assim por exemplo a uma equipa alterar as regras de processamento linguístico em drawpar, sem ter de preocupar com alterações em parwave.
Numa primeira fase foram realizadas as alterações necessárias para que o sistema pudesse ser compilado num PC a correr uma variante de UNIX (Linux). Na realidade foram necessárias apenas algumas alterações nos módulos responsáveis pelo envio do sinal de fala ao sistema de audio.
Com o objectivo de poder compilar o DIXI em MS-DOS utilizando um compilador de 32 bits para gerar uma aplicação MS-DOS (32 bit DOS extender), pensou-se em criar apenas um só executável spdixi ("single process DIXI"), visto o MSDOS não correr múltiplos processos. Assim, numa segunda fase, foram realizadas as alterações necessárias para se gerar apenas um processo constituído pela junção de drawpar com parwave. Como cada um destes programas possuía diversas opções na linha de comandos, foi necessário separar o processamento destas opções do resto das rotinas que constituíam cada um desses módulos. Utilizando diferentes opções numa "makefile" é possível criar os três executáveis a partir de uma mesma árvore de directorias com todos os programas-fonte do projecto. Para compilar para MSDOS 32 bits, utilizou-se o compilador DJGPP que é semelhante ao utilizado em UNIX ("gcc"). Foi apenas necessário criar um módulo que contivesse as rotinas responsáveis pela comunicação com a placa de som do PC, a Sound Blaster 16. Este módulo foi optimizado com a utilização de técnicas de "double-buffering" para permitir o máximo de paralelismo entre a síntese de um segmento e a sua audição. Foram criadas algumas rotinas que permitem terminar a aplicação libertando de forma adequada o sistema de audio. Este sub-módulo foi especialmente criado, tal como previsto no plano inicial, para a placa Sound Blaster 16, de utilização corrente e de custo relativamente baixo, comparado com outras na altura existentes no mercado.
Após estas duas fases, a mesma árvore de directórios podia gerar os três executáveis, drawpar, parwave, spdixi (e ainda o scyla) em SUN4, Linux (i486) e MSDOS (DOS extender GO32 do compilador DJGPP).
Numa terceira fase pretendeu-se efectuar o transporte para Windows. Para facilitar a reutilização dos programas-fonte, optou-se pela compilação em Windows 32 bits (à semelhança das versões em Linux e MSDOS). Isso significa que a versão Windows poderá correr em Windows NT, Windows 95 ou então Windows 3.11, desde que se acrescente o pacote WIN32s. Em primeiro lugar havia que reescrever os módulos do sistema de audio para utilizar as funções Multimédia do Windows. Novamente aqui houve a preocupação de paralelizar ao máximo a síntese e a audição de um segmento de fala. Em segundo lugar, foram separadas as funções de inicialização dos diferentes módulos do resto do processamento. Um dos problemas surgidos na passagem do DIXI para o ambiente Windows foi o problema do "input/output". Até aqui a aplicação lia texto do "stdin" (teclado ou ficheiro), escrevendo eventuais mensagens de erro no "stdout" ou "stderr" (ecrã). Este procedimento não podia ser utilizado no Windows sem que se reescrevesse grande parte do código e fossem criadas janelas de emulação de terminal. Assim optou-se por transformar as rotinas de "input" (do SCYLA) de forma a puderem processar "strings". As rotinas de "ouput" não foram alteradas e portanto não é possível a visualização de quaisquer mensagens de erro.
Outro problema surgido na implementação inicial para Windows 3.11 está relacionado com o mecanismo de mensagens do Windows que foi feito de forma a que uma aplicação processe o mais rapidamente possível uma mensagem e de seguida retorne o controlo do processador para que outra aplicação possa correr. Para adaptar o DIXI a este mecanismo, designado por "multitasking" cooperativo, era necessária uma grande alteração na estrutura do código, obrigando à existência de programas-fonte separados: um para UNIX/MSDOS e outro para Windows. Tentou-se então interromper o processamento enquanto se esperava por uma mensagem do sistema multimédia do Windows avisando que mais um bloco tinha sido descarregado para a placa de som. O programa sintetizava bloco a bloco e enviava-os para as rotinas multimédia do Windows ficando à espera que um bloco terminasse de ser ouvido para sintetizar o próximo. Para evitar os tempos mortos utilizou-se novamente uma técnica de "double-buffering". Esta estratégia tinha o inconveniente de por vezes a síntese ser interrompida porque outra aplicação Windows tomou conta do processador por tempo demais.
Decidiu-se então utilizar uma outra estratégia: se a frase a sintetizar for pequena, o tempo que o DIXI demora para processa-la é pequeno. Por isso optou-se por não cooperar com as restantes aplicações do Windows tomando conta do CPU durante todo o período de síntese. Isto não é tão grave como parece porque as aplicações de 32 bits no Windows 95 funcionam em multiprocessamento preemptivo, ou seja correm apenas durante a fatia temporal que o sistema operativo lhes designa, sendo a comutação para outra aplicação efectuada mesmo que aplicação corrente não liberte o CPU.
Foi então desenvolvida uma aplicação de demonstração em Windows (32 bits) utilizando os mesmo programas-fonte do projecto, acrescentando no entando novos programas-fonte para cobrir as particularidades do Windows. Continua no entanto a ser possível integrar qualquer alteração realizada ao nível de processamento linguístico em qualquer das arquitecturas/plataformas para as quais o sistema pode ser compilado: Unix (Sun4,Linux), MSDOS e Windows 32, bastando para tal recompilar o programa. A aplicação de demonstração permite sintetizar um texto contido num ficheiro, ou escrito numa caixa de diálogo.
Para permitir a sua utilização em outras aplicações Windows, decidiu-se transformar a aplicação de demonstração desenvolvida, numa biblioteca de ligação dinâmica (DLL). Para tal foi criado um sub-módulo de interface da DLL que contém apenas uma rotina de inicialização, outra de síntese e outra de terminação/fecho. Assim, qualquer aplicação desenvolvida para Windows 32 bits poderá utilizar o "DIXI.DLL" simplesmente chamando estas três funções ("dixi_init", "dixi_play", "dixi_done"). Foram criados ainda ficheiros de projecto para compilação com o Borland C++ v4.xx e com o Microsoft Visual C++ v2.0. A DLL criada foi utilizada com sucesso no editor de texto EDIXI, criado em Visual C++ 1.5 (16 bits) e posteriormente compilado para 32 bits com o Visual C++ 2.0 e "ligado" à biblioteca dinâmica "DIXI.DLL".
Voltar ao início do documento5. Interface com o utilizador (EDIXI)
O editor de texto é uma peça fundamental neste tipo de aplicações, uma vez que é através da escrita que se torna possível a comunicação pela fala. O conjunto de requisitos inicialmente definidos (funções elementares de edição de texto + procedimentos de aceleração da velocidade de geração das mensagens + facilidades de síntese) é dificilmente compatível, no entanto, com o desenho de uma sistema de baixo custo que possa correr em qualquer computador pessoal, em ambiente MSDOS. Para tornar possível uma avaliação global dos problemas que poderiam surgir e procurar soluções de compromisso que tivessem em consideração as prioridades dos utentes, foi desenvolvida, logo no início do projecto e respeitando integralmente os prazos previstos, uma primeira versão básica do editor de texto para correr nesse ambiente. Como os trabalhos de adaptação de DIXI ainda estavam em curso, os ensaios de integração de capacidades de síntese foram feitos utilizando um sintetizador de fala para a língua inglesa, desenhado para funcionar com placas de som compatíveis com a Sound Blaster da Creative Labs e que se apoia no pacote de software que acompanha a referida placa.
A primeira versão da aplicação (EDIXI 1.0) continha um conjunto de funções elementares, comuns a qualquer outro editor, como as que permitem escrever um texto no ecrã, guardá-lo em disco, modificá-lo e ainda formatá-lo e imprimi-lo. As funções relacionadas com o tratamento de texto eram, no entanto, muito mais limitadas do que é habitual, dada a necessidade de memória disponível para o sistema de síntese e para os procedimentos de aceleração. A introdução de procedimentos de aceleração (tarefa II.2) e de controle do teclado (tarefa II.3) foi antecipada, podendo estes ser activados ainda no decorrer do primeiro ano do projecto.
A necessidade de efectuar o transporte do sistema para ambiente Windows (cf. §6, abaixo) obrigou, no entanto, a reescrever quase integralmente os programas-fonte do editor de texto. Não tendo a primeira versão sido concebida e testada para este ambiente, tornava-se, de facto, mais prático e económico escrever um novo editor do que alterar a anterior versão.
A nova versão (EDIXI 2.0) baseia-se na anterior, tendo sido, no entanto, abandonadas algumas opções a nível da formatação e impressão dos textos e criadas novas opções que se julgaram de maior utilidade para o fim a que o sistema se destina EDIXI 2.0, por exemplo, é capaz de trabalhar com mais do que um documento ao mesmo tempo, o que não acontecia antes.
Uma vez que as duas versões do editor foram já detalhadamente descritas em relatórios anteriores, limitar-nos-emos aqui apenas a uma descrição sumária.
Como se pode verificar pela figura 6, o espaço de trabalho desta versão assemelha-se ao de qualquer software desenvolvido em ambiente Windows e é composto por 5 áreas diferentes: Título, Barra de Menus, Barra de Trabalho, Documento e Barra de Estado.

Fig. 6 - Espaço de Trabalho de EDIXI
5.2. Procedimentos de aceleração
Como tem vindo a ser repetidamente referido, um dos principais problemas das crianças com deficiência motora e de fala é o da velocidade de geração de mensagens, sendo necessário prever um conjunto de mecanismos que permitam acelerá-la. Um desses mecanismos é a possibilidade de utilização de abreviaturas, já disponível em anteriores versões do sistema DIXI, utilizando o dicionário de expansão de a que o módulo de normalização faz apelo. Por razões de eficiência, este dicionário é compilado com o programa, sendo possível, contudo, torná-lo directamente acessível ao utilizador em futuras versões, se tal se vier a verificar necessário. Repare-se, com efeito, que uma das motivações para a capacidade de utilização de abreviaturas é a redução do número de teclas em que é necessário carregar para escrever uma palavra e EDIXI 2.0 inclui um mecanismo de consulta a léxicos de frequência, com esse mesmo fim e possivelmente mais eficaz. Assim, se for essa a opção seleccionada, quando o utilizador escreve a primeira letra de uma palavra, abre-se imediatamente uma janela em que aparecem ordenadas por ordem decrescente as dez palavras mais frequentes do léxico começadas por essa letra. Se a palavra desejada constar dessa lista, basta pressionar a tecla correspondente ao seu número de ordem para que apareça integralmente escrita no documento (cf. Fig. 7). Se não constar, escreve-se a segunda letra e assim sucessivamente, sendo a lista actualizada de cada vez que uma nova letra é introduzida. Trata-se de um procedimento de aceleração já ensaiado em aplicações semelhantes desenvolvidas e testadas para outras línguas, indicando esses testes que este modo de escrita permite uma economia de movimentos da ordem dos 40% (Beukelman et al., 1985).
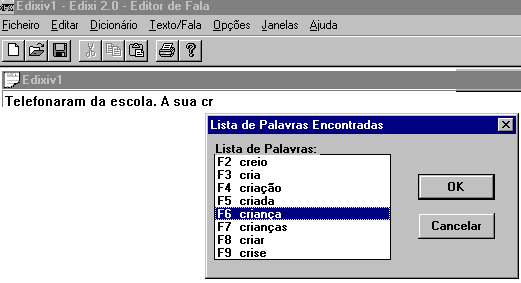
Fig.7 - Lista de palavras mais frequentes
Por defeito, o sistema utiliza um léxico constituído a partir do corpus de frequência do Português Fundamental, desenvolvido pelo CLUL (Bacelar et al., 1987). Podem ser utilizados, contudo, léxicos definidos pelo utilizador, contendo o menu Dicionário um conjunto de opções para facilitar essa tarefa (cf. Fig.8).

Fig. 8 - Menu Dicionário
A opção Abrir abre o dicionário que o utilizador pretende utilizar, Inserir e Apagar permitem-lhe inserir e apagar as entradas do dicionário activo, sendo possível gravá-lo com o mesmo nome (opção Gravar) ou criar um novo dicionário (opção Gravar Como). Estas facilidades do sistema permitem, nomeadamente, que em conjunto na classe, ou isoladamente, os utilizadores possam preparar dicionários diferentes para utilizar em diferentes contextos.
Seja qual for o léxico utilizado, o utilizador pode sempre editá-lo para alterar as frequências de ocorrência e, se não o fizer, o sistema tem capacidade de aprendizagem e estas vão sendo adaptadas à medida que o sistema é utilizado.
Para além de permitir uma redução do esforço físico que é necessário despender na geração de mensagens, a consulta de léxicos contribui, também, para reduzir o número de erros de dactilografia que resultam directamente da falta de coordenação motora. Para minorar este problema, foram introduzidas outras facilidades: a pressão continuada sobre uma tecla, por exemplo, não é interpretada como uma sequência de caracteres idênticos mas como um único caracter.
Em situações de comunicação interactiva, consegue-se, ainda, uma melhoria significativa da capacidade de intervenção, activando glossários com frases pré-preparadas para utilização em diferentes contextos. A opção Inserir Frase no menu Dicionário (cf. Fig. 8) permite seleccionar e inserir no documento frases pré-preparadas, num ficheiro de configuração em disco. Frases ou textos inteiros podem também ser pré-preparados pelo utilizador, bastando carregar o ficheiro desejado para o espaço Documento (opção Abrir do menu Ficheiros). .
5.3. Activação do sintetizador
O menu Texto-Fala contém várias opções de activação do sintetizador, como a Fig.9 ilustra, permitindo sintetizar um texto seleccionado, a linha em que se encontra posicionado o cursor ou todo o texto contido no documento activo. A opção Documento, permitindo sintetizar um documento não activo, está ainda inactiva nesta versão. A opção Frase permite sintetizar frases sem as inserir num documento.

Fig. 9 - Menu Texto/Fala
Voltar ao início do documentoA utilidade de testes realizados sobre materiais sintéticos é actualmente incontroversa. Estes são fundamentais, quer como meio de análise durante o processo de desenvolvimento e optimização dos sistemas de síntese quer como meio de avaliação do seu desempenho global ou parcial. O desenvolvimento de materiais estandardizados e de metodologias de avaliação tem sido, por conseguinte, objecto de especial atenção nos últimos anos, nomeadamente a nível europeu (ex.:projectos SAM, EAGLES, EUROCOCOSDA, etc.), sendo múltiplos os testes construídos e já aplicados para avaliar o desempenho dos sintetizadores a nível do desempenho dos seus diferentes módulos, assim como da inteligibilidade segmental, qualidade global e funcionalidade para aplicações específicas (para uma discussão de diferentes aspectos metodológicos, tipos de testes, programas disponíveis para os elaborar, etc., veja-se Pols et al.(1992), EAGLES (1995), assim como as referências aí indicadas).
Dado o estádio de desenvolvimento do sistema DIXI e o investimento que se julgava possível fazer a nível da melhoria da sua qualidade, não foi prevista uma avaliação formal do sistema no âmbito deste projecto, mas apenas a realização de alguns testes por uma turma de crianças do CPCCG.
Foi contudo realizada uma avaliação formal do desempenho do módulo de transcrição fonética. Este módulo, sem dúvida o mais elaborado do sistema e aquele em que foi feito um maior investimento no quadro de outros projectos, já tinha sido avaliado em ocasiões anteriores, existindo, por conseguinte, os materiais de teste necessários. Apesar do seu desempenho se situar ao nível dos 94% de resultados correctos (cf. Trancoso et al. 1994), verificou-se que algumas das suas regras não eram efectivamente aplicadas devido a questões de ordenação. Tendo sido feitas as alterações julgadas necessárias para resolver este problema, impunha-se, naturalmente, a sua reavaliação.
6.1. Avaliação do módulo de transcrição fonética
Para o teste do módulo de transcrição fonética (grafema-fone) foi utilizado um corpus designado por PF_Fone (Viana et. al, 1992), construído sobre o do Português Fundamental, já referido acima (cf. Bacelar et. al, 1987). Este é constituído por 26000 entradas diferentes, correspondentes a 715000 formas de citação e formas flexionadas e a mais de 3 milhões de grafemas. Para além das entradas em ortografia corrente e das respectivas frequências de ocorrência, PF_Fone contém também transcrições fonéticas correspondentes à sua pronúncia não marcada por falantes da região centro, em que são indicadas as fronteiras de sílaba e a posição do acento. Todas as entradas desse corpus foram verificadas e corrigidas pelo menos por 3 falantes nativos dessa variedade, com prática de transcrição.
O desempenho do sistema a este nível pode ser medido comparando as transcrições geradas pelo sistema sem recurso ao dicionário com as que são contempladas no corpus. No que diz respeito ao acento, não houve quaisquer alterações em relação a versões anteriores. O sistema assegura uma correcta atribuição do acento em 99% dos casos e os erros que comete apenas podem ser evitados se as formas correspondentes forem incluídas no dicionário. De facto, como a ortografia portuguesa deixou de marcar com acento grave a sílaba acentuada da base nas formas derivadas em -mente e -Z-avaliativos, foi criada uma situação de ambiguidade que não é resolúvel de outro modo. Para acentuar correctamente a maior parte destas formas, o sistema faz apelo a estas terminações considerando como base as sequências que se encontram à sua esquerda. Acentua, assim, correctamente palavras como sozinho, sezinha e pezinho (sòzínho, sèzinha e pèzinho), mas atribui erradamente um acento secundário a cozinha, semente, etc., que têm de ser incluídas no dicionário como excepções. É necessário incluir nele, também, as formas terminadas em -ic{o,a}(s) em que este sufixo é um diminutivo para que o sistema acentue mafarricozinho como mafarrìcozínho e não como mafárricozinho, à semelhança de fábricazinha, hermèticaménte, etc.
No que diz respeito à transcrição propriamente dita, as alterações introduzidas produzem transcrever correctamente 25458 entradas do corpus, assegurando actualmente este módulo um desempenho da ordem dos 98%. A maior parte dos erros observados, dizem respeito a /e/ /E / /o/ / / acentuados e a casos que o sistema interpreta como compostos de radicais (ex. fil-o-sofia) não elevando a vogal de ligação.
6.2 Avaliação do sistema por crianças do CPCCG
As crianças e jovens com Paralisia Cerebral têm uma disfunção neuromotora que resulta de uma lesão cerebral que afecta o cérebro em período de desenvolvimento pré ou perinatal e primeiros anos de vida.
A deficiência motora é habitualmente a que predomina com dificuldade no controlo da postura e do movimento, podendo haver paralisia, incoordenação motora e movimentos involuntários. É frequente, contudo, a associação de outras incapacidades, défice de visão e audição e alterações da sensibilidade, perturbações de linguagem e fala, défice cognitivo, perturbações emocionais e de comportamento e epilepsia.
Existem vários graus de deficiência e as manifestações clínicas são muito diferentes e assim cada criança exige um programa de reabilitação e apoio educativo individualizado e específico.
Em muitas situações, há dificuldade no controlo dos membros superiores e na expressão oral, sendo muito importantes os meios aumentativos de comunicação e as tecnologias de apoio para dar à criança possibilidades de desenvolver as suas potencialidades.
O reforço verbal é fundamental na aquisição de linguagem e portanto a fala digitalizada e muito particularmente a síntese de fala são tecnologias de apoio essenciais para favorecer o desenvolvimento da linguagem e a aprendizagem escolar.
Um dos principais objectivos dos testes que nos propusemos realizar era o de envolver as crianças no processo de construção deste utensílio, evitando atitudes de recusa liminar, habituais quando a qualidade da fala sintética está ainda longe de poder ser confundida com uma voz natural. Outro objectivo fundamental era o de verificar em que medida um sistema deste tipo, apesar das suas limitações, poderia ou não funcionar como meio auxiliar de comunicação e de apoio à aprendizagem
6.2.1 Caracterização da turma experimental
A turma é constituída por nove crianças, das quais sete são do sexo masculino e duas do sexo feminino, com idades compreendidas entre os sete e os onze anos.
De um ponto de vista clínico, são nove as crianças com paralisia cerebral: cinco tetrapararésias espásticas com atetose e/ou distonia; uma distonia; duas atetose; uma diplégia espástica.
Pela análise dos processos destas crianças, pode-se concluir que a etiologia mais referida é a perinatal, seis casos de anóxia, dois dos quais associados à prematuridade. Nos restantes três casos, os processos referem sequelas de traqueostomia, prematuridade e etiologia desconhecida.
Indepedência / autonomia
É uma turma com casos pesados do ponto de vista motor. Apenas duas crianças são independentes na locomoção: uma com canadianas e outra com andarilho Sete crianças necessitam de cadeira de rodas.
Ao nível da função da mão, apenas duas destas crianças têm uma preensão razoável que lhes possibilita a escrita manual.
No que se refere às actividades da vida diária (A.V.D), sete crianças são completamente dependentes.
Cinco destas crianças utilizam para comunicar, um Sistema Alternativo/Aumentativo de Comunicação (S.A.A.C).
No que se refere às ajudas técnicas utilizadas pelas crianças desta classe, seis utilizam cadeira de rodas, duas andarilho ou cadeira de rodas e uma outra canadianas.
Cinco crianças usam tabelas de comunicação.
Sete crianças necessitam do computador como meio de concretização de actividades escolares. Quatro destas crianças, utilizam ainda este recurso, como único meio de se tornarem independentes na comunicação.
Cinco destas crianças frequentaram o jardim infantil da Instituição e apenas três entraram directamente para o escola do 1º ciclo do ensino básico.
É uma turma que globalmente se encontra ao nível de uma primeira fase: cinco crianças estão a fazer a aprendizagem da leitura e escrita e as restantes a um nível propedêutico, com programas intensivos de comunicação.
Caracterização sócio familiar
O nível económico e sócio cultural da turma é no geral médio/ baixo .
A atitude familiar é muito heterogénea, assumindo vários níveis de aceitação e expectativas.
Das crianças que constituem a turma, uma vive só com a mãe, outra com a mãe, a avó e um tio, uma com uma ama, porque o pai se encontra a trabalhar fora do país e as restantes com os pais ou com os pais e irmãos.
Fizeram parte deste estudo todos os alunos da classe, pois o EDIXI foi utilizado, ao longo do ano, em contexto pedagógico em actividades de grupo, como reforço das iniciativas de comunicação de todas as crianças e, individualmente, como recurso didáctico, com as crianças que no início da experiência se encontravam em fase de iniciação do processo de aprendizagem da leitura escrita.
EDIXI foi também utilizado em sessões de comunicação em grupo, em situação lúdica, ao longo dos nove meses de experimentação. Estas sessões realizaram-se com uma frequência de três vezes por semana, a partir da criação sistemática de oportunidades de comunicação, em que se privilegiou uma escuta activa por parte do adulto. Recriando a interacção e facilitando a tomada de iniciativa por parte de todas as crianças, estimulávamo-las a ser mais activas, encorajando-as a relatar factos, fazer perguntas e a não se limitarem apenas a dar respostas.
A partir do desenvolvimento deste tipo de comunicação, que cada criança procurava fazer segundo o seu ritmo e utilizando o seu meio de expressão, fomos introduzindo o programa, como uma "máquina que fala", criando assim a necessidade e o interesse da aprendizagem da leitura e escrita, como requisito indispensável para a sua correcta utilização.
O programa foi também utilizado em sessões de grupo mais estruturadas como por exemplo: sequências de histórias, criação de histórias a partir de imagens, associação frase / imagem, associação imagem / palavra, proposta de estruturação correcta de frases absurdas no aspecto sintáctico.
De um modo geral, as crianças gostam de utilizar o sistema como ferramenta de aprendizagem e empenharam-se com entusiasmo na descoberta das suas falhas, anotando os "erros" para que pudessem ser corrigidos .
Uma das tarefas em que se empenharam foi a de teste do desempenho do sistema para as formas contidas nas tabelas de comunicação que utilizam, tendo detectado 52 erros em cerca de 400 formas. Na maior parte dos casos, tratava-se de realizações inadequadas de consoantes líquidas que impediam a identificação das palavras. Noutros, no entanto, apenas de realizações que não consideraram naturais e identificaram como "estrangeiras".
Apenas uma das crianças reunia as condições físicas, comportamentais e nível de conhecimentos, que lhe permitiram utilizar o sintetizador mais autonomamente e foi, sem dúvida, a que mais beneficiou com a sua utilização, tendo sido possível observar uma melhoria significativa nos seguintes níveis de desempenho que constam dos procedimentos de avaliação global das crianças:
- segmentação progressiva do contínuo sonoro que é a frase.
- compreensão da leitura
- análise silábica, descriminação e identificação de fonemas.
- conhecimento do vocabulário
- capacidade de estruturar correctamente as frases sob o ponto de vista sintáctico.
- correcção ortográfica.
Globalmente, observou-se, ainda, uma maior motivação para as aprendizagens e um maior desejo de comunicar.
Voltar ao início do documentoPara utilizar o computador de uma forma autónoma, um grande número de crianças com paralisia cerebral (neste caso a grande maioria da turma) necessita de programas de emulação de teclado que permitam accioná-lo indirectamente executando movimentos grosseiros das mãos, da cabeça, da boca, etc. Como existem no mercado vários programas de emulação de teclado, não se julgou conveniente investir nesta área no âmbito do projecto. Procurou-se, no entanto, testar a possibilidade de acoplamento de EDIXI a um destes dispositivos. O teste foi realizado com um sistema, denominado WIVIK2, desenvolvido no Canadá pelo The Hugh MacMillan Rehabilitation Centre. Este visualiza no ecrã um teclado convencional e possui diferentes modos de selecção de teclas para diferentes graus de gravidade da deficiência motora. No primeiro modo (click), a tecla é seleccionada utilizando as 4 setas do computador para movimentar o selector e carregando no rato para sinalizar a escolha. No segundo modo (dwell), é definido um tempo mínimo de permanência do selector sobre uma mesma tecla, excedido o qual esta é automaticamente seleccionada, dispensando-se assim, o esforço de carregar no rato. No terceiro modo (scan), é feito o varrimento do ecrã de uma forma programável, sendo a selecção feita quer através de teclas especiais (F11 e F12) quer através de interruptores ligados à porta série ou paralelo do computador.
Na parte superior do ecrã, é visível um menu das palavras mais frequentes começadas pelos caracteres já introduzidos. Como se torna confuso visualizar dois menus de predição simultaneamente e WIVIK2 pode utilizar outros léxicos de frequência em vez do que é originalmente fornecido com o sistema, pode inibir-se este menu de EDIXI e carregar directamente o léxico do Português Fundamental com WIVIK2. Na versão de demonstração a que tivemos acesso, não há possibilidade de gravar este léxico de uma forma permanente, mas espera-se poder vir a testar brevemente o sistema EDIXI-WIVIK2 com as crianças do CPCCG com deficiências motoras de maior gravidade. Qualquer outro emulador de teclado com características semelhantes poderá, no entanto, vir a ser utilizado.
Voltar ao início do documento8. Principais resultados e perspectivas futuras
O principal resultado do projecto EDIFALA é, sem dúvida, o da existência de uma aplicação como EDIXI, contemplando as necessidades de pessoas com deficiência motora e de fala e com capacidade de síntese do Português Europeu.
Embora seja necessário continuar a investir em projectos que permitam continuar a melhorar a qualidade da voz sintética, consideramos que foram feitos importantes progressos nesse sentido, tendo sido realizado um conjunto de estudos sobre a língua portuguesa que permitiram um melhor controle da parametrização tanto segmental como prosódica. As soluções encontradas de um ponto de vista da engenharia são de especial importância. O facto de o sistema de síntese se encontrar transformado numa biblioteca de ligação dinâmica (DLL) e não necessitar de harware específico, torna-o facilmente executável a partir de outras aplicações a correr em ambiente Windows. Pode também ser facilmente recompilado, sendo possível continuar a melhorá-lo progressivamente e fornecer novas versões sempre que os progressos a nível da qualidade da síntese o justificarem.
São três os níveis em que estamos presentemente empenhados na melhoria do sistema DIXI: processamento linguístico e geração das funções temporais dos parâmetros de controle do sintetizador, aumento do número de vozes sintéticas disponíveis e alargamento do seu leque de aplicações.
Grande parte das deficiências observadas na qualidade e naturalidade da voz sintética estão relacionadas com lacunas nos conhecimentos linguísticos necessários para simular adequadamente o comportamento de falantes nativos do português europeu. Algumas destas lacunas devem-se fundamentalmente ao facto de os sistemas de síntese em geral corresponderem a soluções de compromisso entre as capacidades de cálculo e de memória dos computadores pessoais, a necessidade de funcionamento dos sistemas em tempo real e a quantidade e qualidade dos conhecimentos que é possível introduzir e controlar. Como já foi referido atrás, por exemplo, a implementação em tempo real impôs limitações à dimensão dos dicionários utilizados, o que não pôde deixar de se reflectir na qualidade do processamento sintáctico e morfo-fonológico efectuado pelo sistema. Os desenvolvimentos recentes das capacidades dos computadores pessoais permitem, no entanto, encarar a possibilidade de aumentar consideravelmente as dimensões desses dicionários e assegurar análises mais elaboradas.
As lacunas mais graves decorrem, no entanto, do fraco investimento que tem vindo a ser realizado a nível nacional no sentido de promover o desenvolvimento e disseminação de recursos linguísticos básicos para o estudo da língua portuguesa falada. Não só este investimento tem ficado muito aquém do que tem tido lugar para a maioria das línguas da comunidade, como o arranque da investigação básica na área da linguística computacional foi bastante mais tardio. As equipas envolvidas são pequenas e os recursos linguísticos ainda escassos, o que dificulta consideravelmente o treino e teste de sistemas de processamento automático de fala para esta língua.
No âmbito do convénio entre o CLUL e o INESC, tem-se procurado investir nesta área, não só partilhando as tarefas de modo a aproveitar ao máximo o conjunto de competências disponíveis, como promovendo a cooperação com outras instituições tanto nacionais como estrangeiras. De momento, estão em curso ou em fase de arranque, projectos que têm por objectivo a recolha, segmentação e etiquetagem de corpora de fala. Estes não asseguram ainda uma cobertura suficiente dos fenómenos sonoros que é necessário contemplar e só há relativamente pouco tempo começaram a poder ser explorados para fins de estudo e modelização de alguns aspectos parcelares. Só muito recentemente, também, foi possível dispor de pacotes de programas que permitem a sobreposição de parâmetros integralmente sintéticos com parâmetros extraídos da fala natural e a manipulação de ambos de uma forma simples e prática. Estes programas, ainda em fase de teste, são fundamentais para uma correcta determinação da origem dos problemas e podem ser considerados também como recursos básicos para a pesquisa das soluções mais adequadas para procurar resolvê-los.
Ainda que insuficientes, estes recursos abrem sem dúvida novas perspectivas no que diz respeito a uma melhor simulação do comportamento linguístico dos falantes do português europeu. Presentemente, estamos empenhados em utilizá-los para continuar a melhorar a parametrização prosódica e a modelização das interacções entre esta e os fenómenos de coarticulação, tanto a nível da palavra como da frase.
No seu conjunto, a maior lentidão na geração das mensagens, a qualidade relativamente pobre da fala sintética e o facto de as vozes disponíveis serem em número limitado e, por isso, dificilmente personalizáveis, explicam, pelo menos em parte, a relutância sentida por parte da população com deficiência de fala a nível mundial, em utilizar a síntese como sistema de apoio vocal em situações de interacção verbal. No caso de DIXI, não existe, de momento qualquer possibilidade de selecção de voz, uma vez que este apenas simula a de um falante adulto do sexo masculino. Embora a necessidade de dispor de um conjunto de vozes mais adequadas à idade e sexo dos utentes tivesse sido referida logo desde o início do projecto EDIFALA, a proposta original não contemplou quaisquer tarefas envolvendo trabalhos desta índole, dada a escassez dos recursos disponíveis. Entre os nossos objectivos a curto prazo, conta-se agora, no entanto, o alargamento do leque de vozes disponíveis. Antes de fazê-lo é necessário, contudo, ponderar cuidadosamente as vantagens e desvantagens dos modelos de síntese de formantes e de síntese por concatenação de unidades extraídas da fala natural, tendo para esse efeito sido já construído o embrião de um inventário sonoro de segmentos concatenáveis para uma voz feminina. A subdivisão do sistema nos módulos drawpar e parwave facilita já essa tarefa, permitindo não só trabalhar apenas a nível do módulo parwave experimental, como beneficiar imediatamente de todo o investimento já realizado a nível das regras de leitura do texto escrito e da geração das funções de controle do ritmo e da melodia, contidas em drawpar.
Finalmente, há que alargar também o leque de aplicações de DIXI, de modo a poder cobrir outros tipos de deficiência, nomeadamente visual. Embora EDIXI possua já algumas funções de interesse para esta população (possibilidade de controlar o que efectivamente foi escrito ouvindo quer a linha ou o parágrafo em que está posicionado o curso quer todo o documento), pretende-se, como primeiro passo, definir uma interface de programação compatível com a especificação SSIL (Speech Synthesizer Interface_Library). Esta especificação, concebida pela Arkenstone Inc. (http://www.arkenstone.org), define um protocolo normalizado de comunicação entre a aplicação e o sintetizador de fala, permitindo que este funcione com todas as aplicações que respeitem a norma. Actualmente, existe uma gama de aplicações que suportam a especificação SSIL, entre as quais os leitores de ecrã (screen readers) JAWS (http://www.hj.com), WindowEyes (http://www.gwmicro.com/wineyes.html), Verbal-Ease (http://voila.com/verbal.html) e ScreenPower para Windows (http://www.telesensory.com). Esta abordagem permite-nos concentrar esforços no desenvolvimento do sintetizador de fala para o português europeu, utilizando interfaces com o utilizador já disponíveis.
A conversão de texto escrito na linguagem HTML em fala sintética é, por conseguinte, um dos principais objectivos a curto prazo. A utilização de DIXI neste contexto permitirá a invisuais a leitura de documentos disponíveis neste formato, quer na World Wide Web quer em CD-ROM. A qualidade da voz sintética gerada por DIXI terá, contudo, de ser melhorada e o processamento linguístico efectuado terá de ser capaz de favorecer leituras menos monótonas e mais expressivas, sendo imprescindível, para esse efeito, um investimento continuado na investigação fundamental sobre as características específicas da língua portuguesa e sua modelização em computador.
Voltar ao início do documento9. Inter-relação com outros projectos
Como foi referido atrás este projecto serviu de suporte à participação da equipa Portuguesa no projecto "Phrase Level Phonology" (programa HCM - Huma Capital Mobility), cujos trabalhos foram de particular utilidade para uma melhor modelização das relações entre as representações prosódicas e as propriedades dos sons.
Todo o trabalho realizado no âmbito do projecto JNICT-BDFALA foi de especial utilidade, fornecendo os materiais de referência necessários para a modelização de alguns aspectos parcelares. Por seu turno, EDIFALA contribuíu para o levantamento de algumas questões importantes que não estavam suficientemente cobertas no corpus BDFALA, conduzindo a alterações no conteúdo intrínseco de alguns dos seus sub-corpora.. Os estudos de prosódia puseram também em evidência o interesse da recolha de materiais de fala espontânea e de produções de locutores profissionais, motivando a inclusão no corpus BDFALA de excertos de noticiários, entrevistas e debates nos meios de comunicação social.
Voltar ao início do documento10. Teses de Mestrado no âmbito do projecto
No âmbito deste projecto foram integrados os trabalhos de duas bolseiras do programa Ciência, tendo sido elaboradas duas dissertações de Mestrado em Linguística que exploraram aspectos da relação entre a sintaxe e a prosódia :
- A de Isabel Falé, intitulada Fragmento da Prosódia do Português Europeu: as Estruturas coordenadas.
- A de Marina Vigário, intitulada Aspectos da Prosódia do Português Europeu: Estruturas com Advérbios de Exclusão e Negação Frásica.
Ambas foram apresentadas e defendidas com sucesso na Faculdade de Letras da Universidade de Lisboa, tendo as cópias sido enviadas à JNICT em anexo ao último relatório.
Voltar ao início do documentoDurante o último ano do projecto EDIFALA, tentou-se divulgar o mais possível os principais resultados do projecto e demonstrar o protótipo desenvolvido em diferentes contextos, nomeadamente junto de comunidades de pessoas portadoras de deficiências de vários tipos. Para esta tarefa de disseminação de resultados muito contribuiu o convite feito pelo Secretariado Nacional de Reabilitação, através da Drª Irolinda de Oliveira e da Drª Júlia de Vasconcelos, para apresentar informalmente o sistema EDIXI na reunião da Comissão de Leitura para Invisuais, em Outubro de 1996. Este convite surgiu na sequência de contactos encetados durante o encontro ECART, em Outubro de 1995. Esta reunião foi extremamente interessante e motivadora pela discussão de problemas com que diariamente se debatem as pessoas portadores de deficiência visual, por ter permitido ouvir a sua apreciação relativamente ao sintetizador de fala que é mais vulgarizado nesta comunidade (o sistema Apolo) e, também, por ter permitido demonstrar as potencialidades do sistema EDIXI. De facto, embora este sistema tenha sido desenhado especificamente para crianças sofrendo de paralisia cerebral, a sua modularidade e flexibilidade permite uma adaptação relativamente fácil a outros tipos de deficiência. Foi bastante gratificante para a equipa de investigação que desenvolveu o sistema DIXI de raiz para o português europeu ter notado a clara preferência que alguns utilizadores do sistema Apolo (desenvolvido para o inglês e adaptado à nossa língua) demonstraram pela qualidade da voz sintetizada pelo sistema DIXI.
Na sequência desta reunião teve lugar uma outra, mais recentemente, no INESC, com representantes da Associação ACAPO, onde se debateram os problemas de adaptação que acabámos de referir. Resultou também da reunião da Comissão de Leitura um convite extremamente honroso para apresentar o sistema EDIXI na conferência «O Som e a Informação», organizada em 13 e 14 de Dezembro, no Auditório Montepio, pela revista de dinamização cultural da Câmara Municipal de Lisboa. Nesta conferência, estiveram presentes muitos representantes de instituições ligadas a deficientes visuais e, embora com menor representatividade, deficientes auditivos. Mais uma vez, tivemos o ensejo de discutir problemas da utilização de sintetizadores de fala por deficientes visuais e apresentar algumas das ideias que temos para aplicações futuras do sistema DIXI.
Os estudos realizados no âmbito da participação no programa HCM foram objecto de duas comunicações, uma apresentada oralmente no Workshop do projecto "Phrase Level Phonology", em Edimburgo, Outubro de 1996 e outra no XI Encontro da Associação Portuguesa de Linguística , publicada nas respectivas actas.
Para maior divulgação dos resultados deste projecto, este relatório encontra-se acessível no endereço http://speech.inesc.pt/edifala/edifala_pt.html.
Voltar ao início do documento12. Constituição da equipa de investigação
Nesta última fase de execução do projecto a equipa de investigação foi constituída por:
|
CLUL |
M. Céu Viana |
|
|
Isabel Mascarenhas |
||
|
INESC |
Isabel Trancoso |
|
|
Luís Oliveira |
||
|
Pedro Carvalho |
||
|
CPCCG |
M. Graça Andrada |
|
|
M. Helena Rio Tinto |
Allen,, J., M. S. Hunnicutt e D. H. Klatt (1987) - From Text-to-Speech: The MITalk System. Cambridge, Cambridge University Press.
Andrade, Amália (1987) - Um estudo experimental das vogais anteriores e recuadas em português: implicações para a teoria dos traços distintivos. Diss. para progressão na carreira de investigação, CLUL/INIC, Lisboa.
Andrade, E. e M. C. Viana (1985) - "CORSO I - Um Conversor de Texto Ortográfico em Código Fonético para o Português". Relatórios do Grupo de Fonética e Fonologia, nº6, CLUL, Lisboa, Centro de Linguística da Universidade de Lisboa, pp. 1 - 25.
Andrade, E. & M. Céu Viana (1988) - "O ritmo e o acento em português". Comunicação apresentada no II Encontro Regional da APL em homenagem ao Prof. L. F. Lindley Cintra. Lisboa (para publicação).
Andrade, E. & M. Céu Viana (1989) - "Ainda sobre o ritmo e o acento em português". Actas do IV Encontro Nacional da APL, Lisboa, APL, 1989, pp. 3-15..
Andrade, E. & M. C. Viana (1993) - "Sinérese, Diérese e Estrutura Silábica". Actas do IX Encontro da Associação Portuguesa de Linguística, Coimbra, Outubro de 1993. Lisboa, APL, 1994, pp. 31 - 42.
Bacelar do Nascimento, F., L. Marques & L. Segura (1987) - Português Fundamental II: Métodos e Documentos. Lisboa, INIC-CLUL
Bailly, G., C. Benoît & T.R. Sawallis (Org.s). Talking Machines: Theories, models and designs. Elsevier Science Publishers, 1992.
Benoît, C., M. Grice & V. Hazan (1996) - "The SUS test: A method for the assessment of text-to-speech synthesis intelligibility using Semantic Unpredictable Sentences". Speech Communication, 18(4): 381-392.
Benoît, C. & L. Pols (1992) - "On the assessment of synthetic speech". In G. Bailly., C. Benoît & T.R. Sawallis (Org.s), Talking Machines: Theories, models and designs. Amsterdam, Elsevier Science Publishers, pp. 435-441.
Beukelman, D. R., K. M. Yorkston & P. A. Dowden (1985) - Communication augmentation: A casebook of clinical management. London, Taylor & Francis.
Carvalho, P., P. Geada e P. Lopes (1992) - "Norm: Normalização de Texto para Português". Relatório interno do INESC.
Carvalho, P., L. C. Oliveira, I. M. Trancoso & M C. Viana (1995) - "A Text-To-Speech Synthesizer Adapted to the Needs of Motor and Speech Handicapped People". Resumo publicado nos Proceedings of the European Conference on the Advancement of Rehabilitation Technology (ECART), Lisboa, Outubro de 1995, pp. 108 - 109.
EAGLES. Report of the spoken language systems working group 5. Technical Report, EAGLES, EAGLES Secretariat, Istituto di Linguistica Computazionale, Pisa, Italia, E-mail: ceditor@tnos.ilc.pi.cnr.it, 1995 (para publicação).
Ellison, M. & M. C. Viana (1996) - "Antagonismo e Elisão de Vogais Átonas Finais em P. E.". In I. Duarte e M. Miguel (Org.s) - Actas do XI Encontro da Associação Portuguesa de Linguística, Vol. III: Gramática e Varia, Lisboa, Outubro de 1995. Lisboa, Colibri-APL, 1996, pp.261-281.
Fourcin, A. (1992) - "Assessment of synthetic speech". In G. Bailly., C. Benoît & T.R. Sawallis (Org.s), Talking Machines: Theories, models and designs. Amsterdam, Elsevier Science Publishers, pp. 431-434.
Holmes, J. N. (1961) - "Research on Speech Synthesis". Joint Speech Research Unit Report, JU11-4, British Post Office, Eastcote, England.
Klatt, D. (1980), "Software for a cascade / parallel formant synthesizer", Journal of the Acoustical Society of America, 67, pp.. 971-995.
Lazzaretto, S. & L. Nebbia (1987), "SCYLA: Speech Compiler for Your LAnguage", Proceedings of the European Conference. on Speech Technology, Edimburgo, Vol.2, pp. 381-384
Oliveira, L. C., M. C. Viana & I. M. Trancoso (1991) - "DIXI - Portuguese Text-to-Speech System". Proceedings of the 1991 European Conference on Speech Technology, Génova, Março de 1991, pp. 1239 - 1242.
Oliveira, L. C., M. C. Viana & I. M. Trancoso (1992) - "A Rule-Based Text-to-Speech System for Portuguese". Proceedings of the 1992 International Conference on Acoustics, Speech and Signal Processing, San Francisco, Março de 1992, pp.73 -76.
Oliveira, L. C. (1996) - Síntese de fala a partir de texto. Dissertação submetida para provas de Doutoramento em Engenharia Electrotécnica, Instituto Superior Técnico, Lisboa.
Pols, L. C. W. & SAM-partners (1992) - Multi-lingual synthesis evaluation methods". Proc. 2nd Conf. on Spoken Language Processing. Banf, Alberta, Canada, Vol. 1, pp. 181-184.
Trancoso, I. M., M. C. Viana, F. M. Silva, G. C. Marques & L. C. Oliveira (1994) - "Rule-Based vs Neural Network Based Approaches to Letter-to-Phone Conversion for Portuguese Common and Proper Names". Proceedings of the International Conference on Spoken Language Processing, Yokohama, Setembro de 1994, pp. 1767 - 1770.
Viana, M. C. (1987) - Para a Síntese da Entoação em Português. Dissertação apresentada para Provas de Acesso à Categoria de Investigador Auxiliar. Lisboa, CLUL-INIC (policopiado).
Viana, M. C. & E. Andrade (1992) - "Uma Questão de Equilíbrio". Actas do VIII Encontro da Associação Portuguesa de Linguística, Lisboa, Outubro de 1992. Lisboa, APL, 1993, pp. 523 - 545.
Voltar ao início do documento


